유니코드 write 함수로 출력
유니코드?
전세계의 문자는 아스키 코드로 표현할 수 없다.
유니코드를 이용해서 표현하게 되는데, 각 문자에는 하나의 유니코드가 할당되어 있다.
유니코드는 인코딩방식에 따라 여러 방식으로 표현되고, 같은 방식으로 디코딩해야 유니코드 해석이 가능하다.
각각의 인코딩방식은 장단점이 있다.
EUC-KR : 2바이트 한글전용 인코딩방식. 일부 한자도 포함된다.
UTF-7 : 그냥 아스키 범위만 표현가능한 유니코드
UTF-8 : 아스키 코드의 범위는 1byte에 넣고, 나머지는 2~4 바이트 가변적인 범위에서 표현된다.
USC2 : 고정 2byte 인코딩
USC4 : 고정 4byte 인코딩
UTF-16 : 문자에 따라 2byte 또는 4byte로 표현한다.
UTF-8
가장 많이쓰이며, 1~4 byte 까지 가변길이 문자이다.
가변길이 문자이기 때문에 문자 자체가 1byte짜리인지, 4byte짜리인지 확인하는 용도로 첫바이트에 표식을 집어넣는다.
7bit 짜리로 표현되는 문자들(ascii는) 첫바이트의 첫비트가 0. 이런식이다.
아직 5, 6번째 바이트를 사용하는 문자는 없지만 더 생길수도 있다.
강제로 사용되는 표식때문에 비트의 손실을 보지만 표현할 수 있는 문자가 무한대라는 부분에서는 가변길이라는게 고정길이보다 유리한 부분이 있다.

write 함수로 출력
1. 출력할곳의 인코딩 방식 확인
vim 터미널에 출력할것이기 때문에 vim이 유니코드를 어떤 인코딩 방식을 사용하는지 알아야한다.
ft_printf에서 유니코드값을 인코딩한뒤 출력하면 결국 vim에서 디코딩 하기 때문이다.
터미널에서 locale 명령을 사용하면 어떤 현재 터미널이 인코딩으로 되어있는지 확인이 가능하다

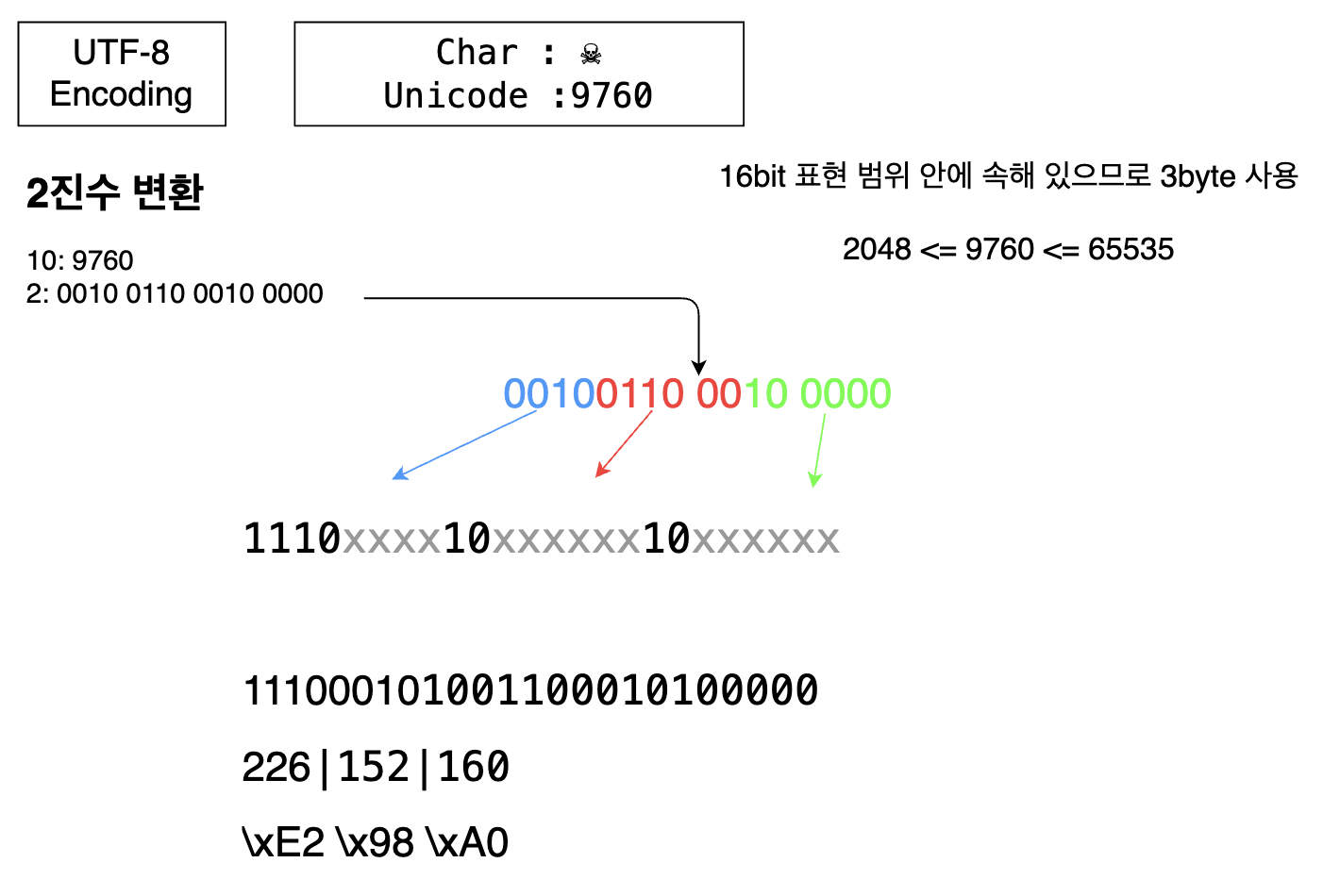
2. 코드포인트 범위 확인
코드포인트 범위에 따라 인코딩 방식이 달라지기 때문에 유니코드가 어떤 범위에 있는지 확인한 후 처리한다.
0 ~ 7F : 7bit =+1bit> 인코딩 후: 1byte
80 ~ 7FF : 11bit =+5bit> 인코딩 후: 2byte
800 ~ FFFF : 16bit =+8bit> 인코딩 후: 3byte
3. 인코딩
utf-8은 그냥 바이트 순서대로 값을 인코딩하면 된다.
전달받은 data 를 6bit씩 or연산 한 후 2bit씩 < shift 연산
data & 3F
3F = 3F << 2
wint_t ft_uni_encode(wint_t data, int *len)
{
wint_t e;
wint_t set;
wint_t set2;
set = 0x3F;
set2 = 0xFF;
if (data > 0xFFFF)
e = 0b11110000100000001000000010000000;
else if (data >= 0x800)
e = 0b111000001000000010000000;
else if (data >= 0x80)
e = 0b1100000010000000;
else
e = 0;
// set 이 계속 앞으로 옮겨지는데, e set 안겹칠때 탈출한다.
// 근데 e = 0일땐 그냥 하면안되는데 겹치지도 않기 때문에 제외한다.
while ((e != 0) && ((e & set) == 0))
{
e |= data & set;
data = data << 2;
set = set << 8;
set2 = set2 << 8;
(*len)++;
}
e = e | (data & set2);
return (e);
}
하지만 중요한부분이 있다. 숫자를 이용해서 문자를 만들어낸것이기 떄문에 바이트 오더링이 반대로 되어있다.
숫자) 10을 저장하는 경우 (0x10번지)10 00 00 00(0x13번지)
문자) "abcd"를 저장하는 경우 (0x10번지)61 62 63 64(0x13번지)
숫자 0b1100000010000000 을 저장했기 때문에
(0x10)10000000 (0x11)11000000 (0x12)00000000 (0x13)00000000 순서로 저장되고
읽을땐 10부터 읽기때문에 잘못된 출력이 발생한다.
바이트를 뒤집어서 저장하거나 저 코드에서 바이트를 뒤집는 함수를 하나 더 만들면된다.
3-1. 바이트를 뒤집에서 저장하는 함수
e = 0b100000001000000011000000;
이렇게 저장하면 11000000 10000000 10000000 00000000 순서로 저장되기 때문에 굳이 뒤에 00000000을 붙이지 않아도 되고 2byte까지만 읽어내면 된다. 사실 4byte까지 읽어도 널이라 상관없긴하다.
문자와 숫자가 거꾸로 저장되어있다는걸 생각해야된다.
<< 쉬프트 연산을 수행하면 메모리상에서는 >> 방향으로 쉬프트된다.
이 방법은 유니코드가 몇바이트인지 미리 알아야하기 때문에 바이트를 뒤집는 함수를 만드는게 나을것같다.
3-2. 바이트를 뒤집는 함수
그냥 1byte씩만 뒤집으면 되는게 아니다.
만약 맨 마지막 바이트가 0인경우 뒤집게되면 첫번째 바이트가 0이되어버려 write(1, &c, 4)로 널을 포함해서 출력해야 값이 보인다.
유니코드는 최대 4byte지만 2byte짜리가 오는경우도 있는데 4번 출력해야 값이 보이는건 이상하기 때문에
맨마지막 바이트가 null이 아닐때까지 size를 줄이고 그후에 뒤집으면된다.
void ft_unicode_ord(void *target, int size)
{
int i;
char tmp;
char *t;
t = target;
i = 0;
while (t[size - 1] == 0)
size--;
while (i < size / 2)
{
tmp = t[i];
t[i] = t[size - i - 1];
t[size - i - 1] = tmp;
i++;
}
}
4. 출력하기 위해서는 setlocale함수로 지역설정을 해줘야한다.
#include <locale.h>
setlocale(LC_ALL, ""); // 컴퓨터의 지역 설정을 따름
setlocale(LC_ALL, "Korean"); // 한국